
Welcome
Partner at BeingBeyond · Lead, Embodied Multimodal Pretraining
I’m a partner at BeingBeyond, where I work closely with Prof. Zongqing Lu on foundation models for general-purpose humanoid robots. I lead projects across the Being-H, Being-M, and Being-VL series, with a focus on embodied foundation models, multimodal pretraining, egocentric human video learning, and humanoid robotics.
Previously, I was a researcher at the Beijing Academy of Artificial Intelligence (BAAI). I received my PhD and bachelor’s degree from Renmin University of China (RUC), advised by Prof. Qin Jin.
My research interests include Embodied Foundation Models, Large Multimodal Models, Egocentric Human Video Learning, and Humanoid Robotics.
Open positions
Join the lab
We are actively recruiting full-time researchers and interns to join our team. If you’re passionate about embodied AI, feel free to reach out.
News
- 2026.07: We introduce Being-H0.8, a latent tactile world-action model at scale for contact-rich robot manipulation.
- 2026.07: One papers is accepted to ACM-MM 2026.
- 2026.06: Three papers are accepted to ECCV 2026.
- 2026.05: Being-H0 is accepted to ICML 2026.
- 2026.04: We present Being-H0.7, a latent world-action model based on 200K human videos.
- 2026.04: Being-H0.5 has been open-sourced.
- 2026.02: Three papers are accepted to CVPR 2026.
Earlier news
- 2026.01: We release Being-H0.5, our latest cross-embodiment foundation VLA.
- 2025.09: Two papers are accepted to NeurIPS 2025.
- 2025.08: We present our Being-M0.5, an improved version of its Being-M0 with real-time controllability.
- 2025.07: Our next version of LMM Being-VL-0.5 is released, including code and checkpoints.
- 2025.07: We release Being-H0, the first VLA pretrained from large-scale human videos with hand motion!
- 2025.06: Three papers are accepted to ICCV 2025.
- 2025.05: We present our first million-level motion model Being-M0, which is accepted by ICML 2025.
Publications
* denotes equal contribution
 BeingBeyond Series
BeingBeyond Series
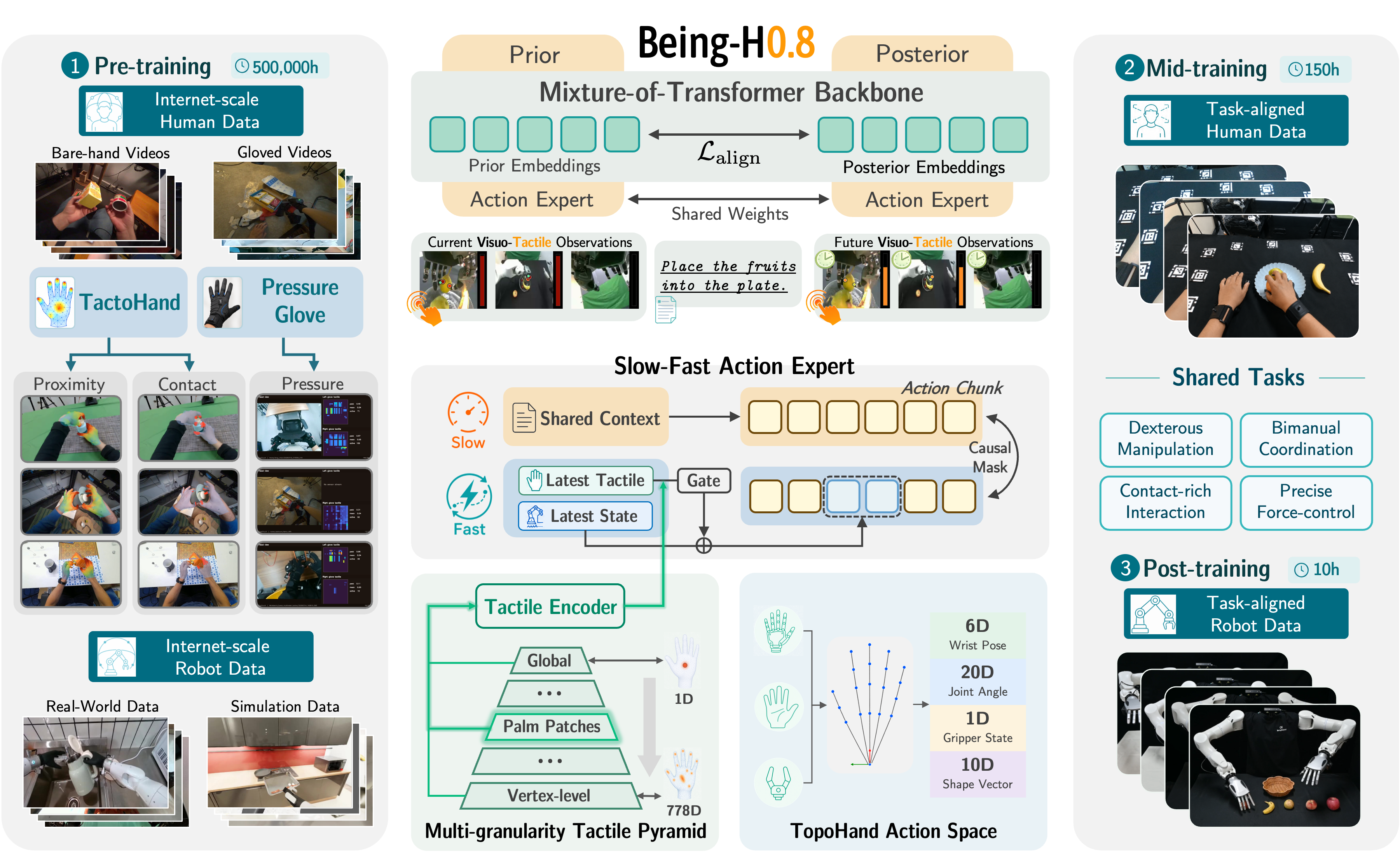
Latent World-Action Models
Future-aware robot control through compact latent world-action modeling.
Our latest general-purpose embodied foundation model extends latent world-action modeling with touch for contact-rich robot manipulation.
Blog | Paper (coming soon)
Previous Being-H0.7 · 2026 · BeingBeyond Team · latent world-action modeling from 200,000 hours of egocentric human videos · Blog · Code (coming soon)
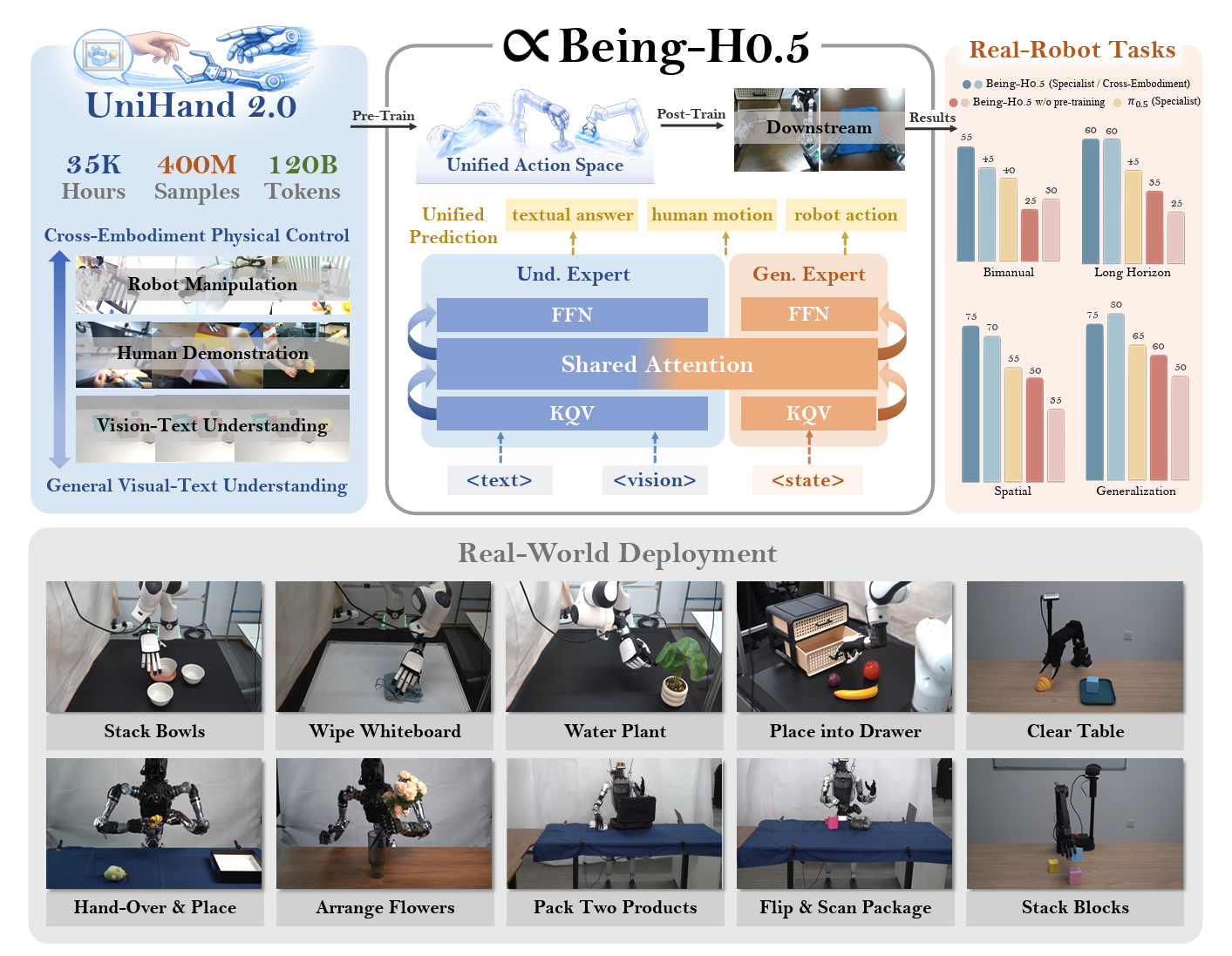
Being-H Series Vision-Language-Action Model
Vision-language-action pretraining from large-scale human videos.
The first VLA pretrained with 10K hours of human videos, spanning 30+ robot embodiments.
Previous Being-H0 · ICML 2026 · BeingBeyond Team · first VLA pretrained with 1K hours of human videos · Blog · Paper · Code · Model
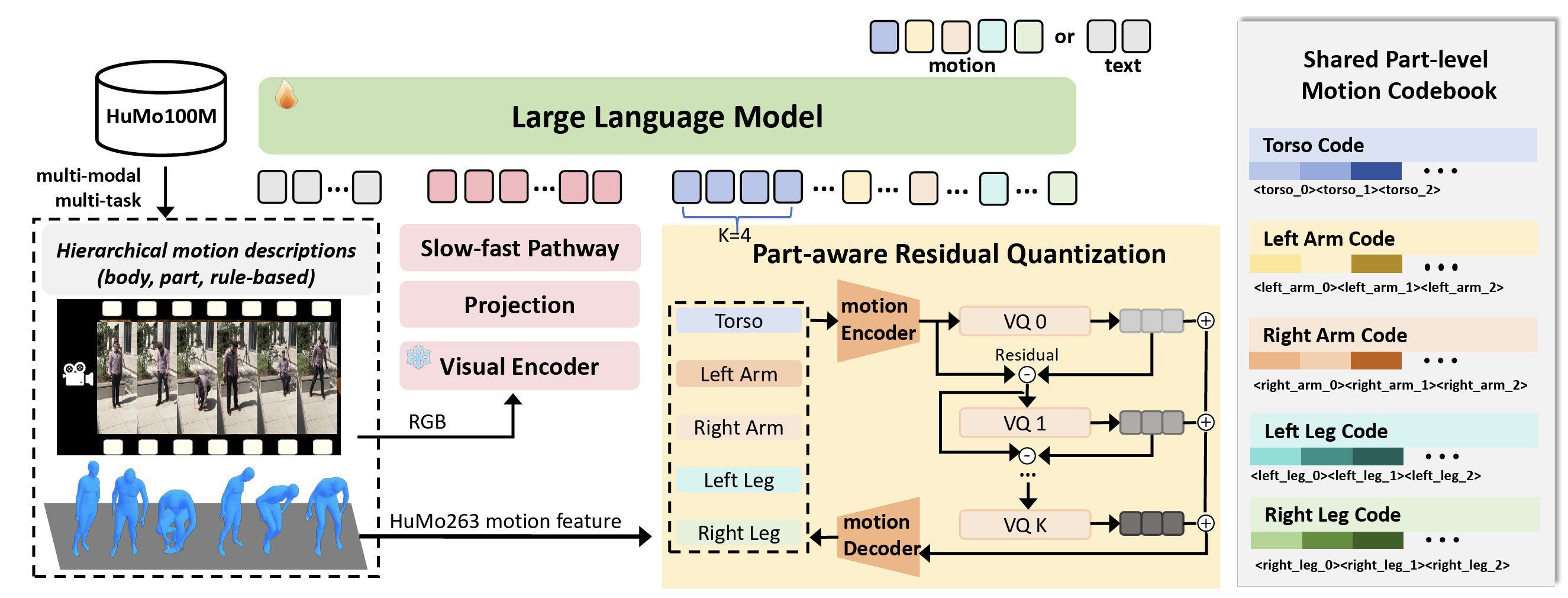
Being-M Series
Large motion generation models for controllable vision-language-motion generation.
Previous Being-M0 · ICML 2025 · Ye Wang*, Sipeng Zheng*, et al. · Paper · Page
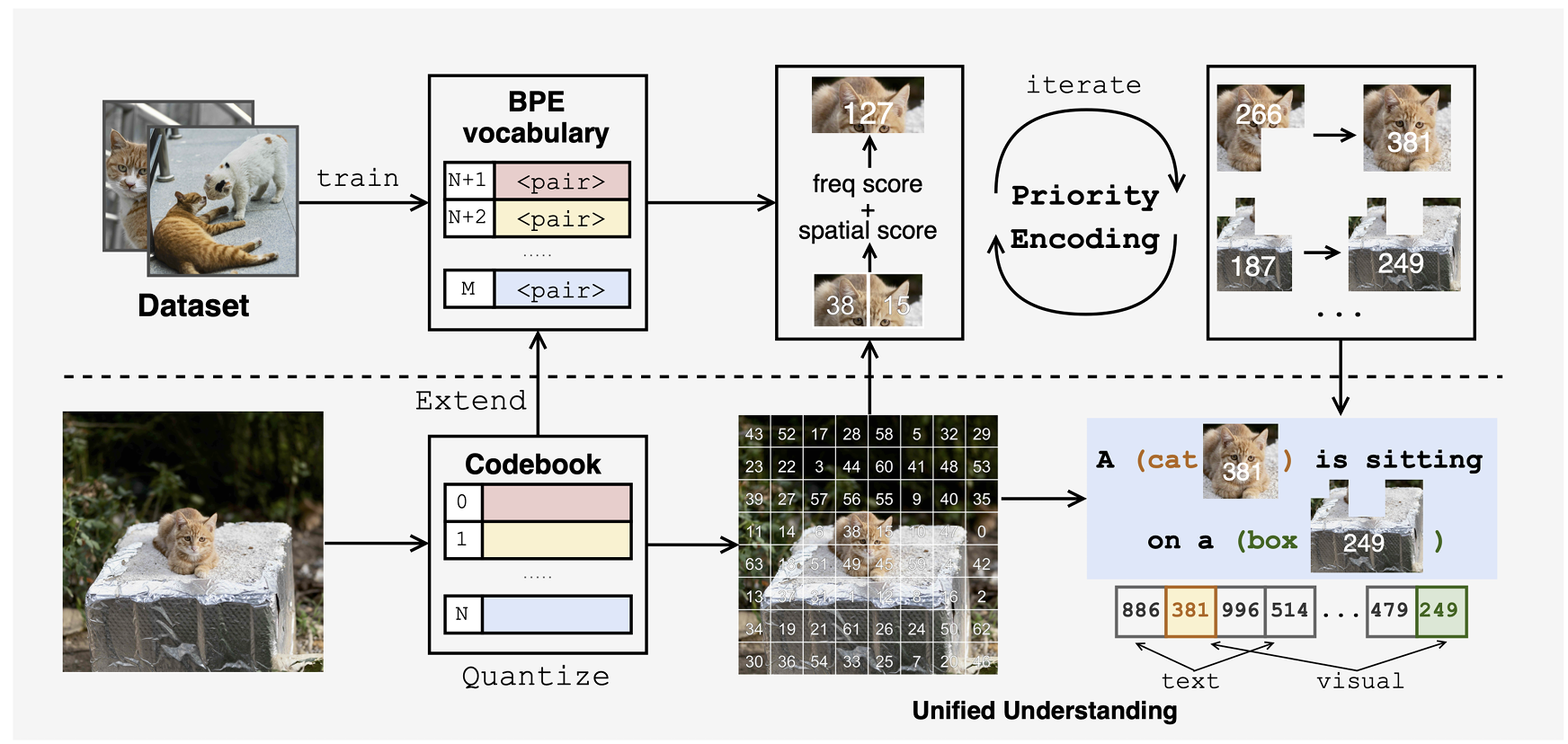
Being-VL Series
Discrete visual tokenization for unified multimodal understanding.
Previous Being-VL-0 · ICLR 2025 · Wanpeng Zhang, Sipeng Zheng, et al. · Paper · Page
Early Work
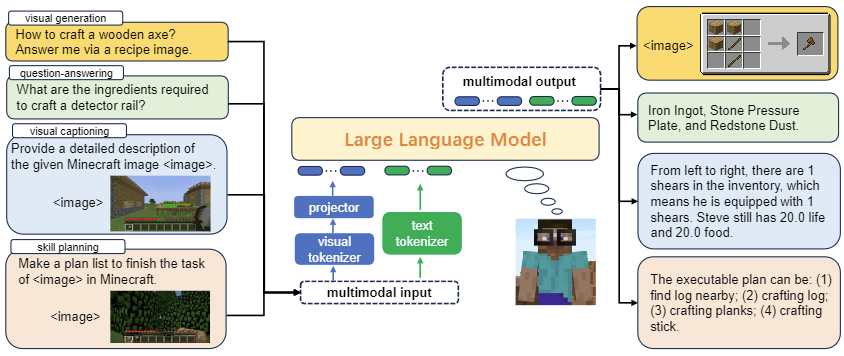
Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds, Sipeng Zheng, Jiazheng Liu, Yicheng Feng, Zongqing Lu
ICLR24 (Spotlight 5.02%)
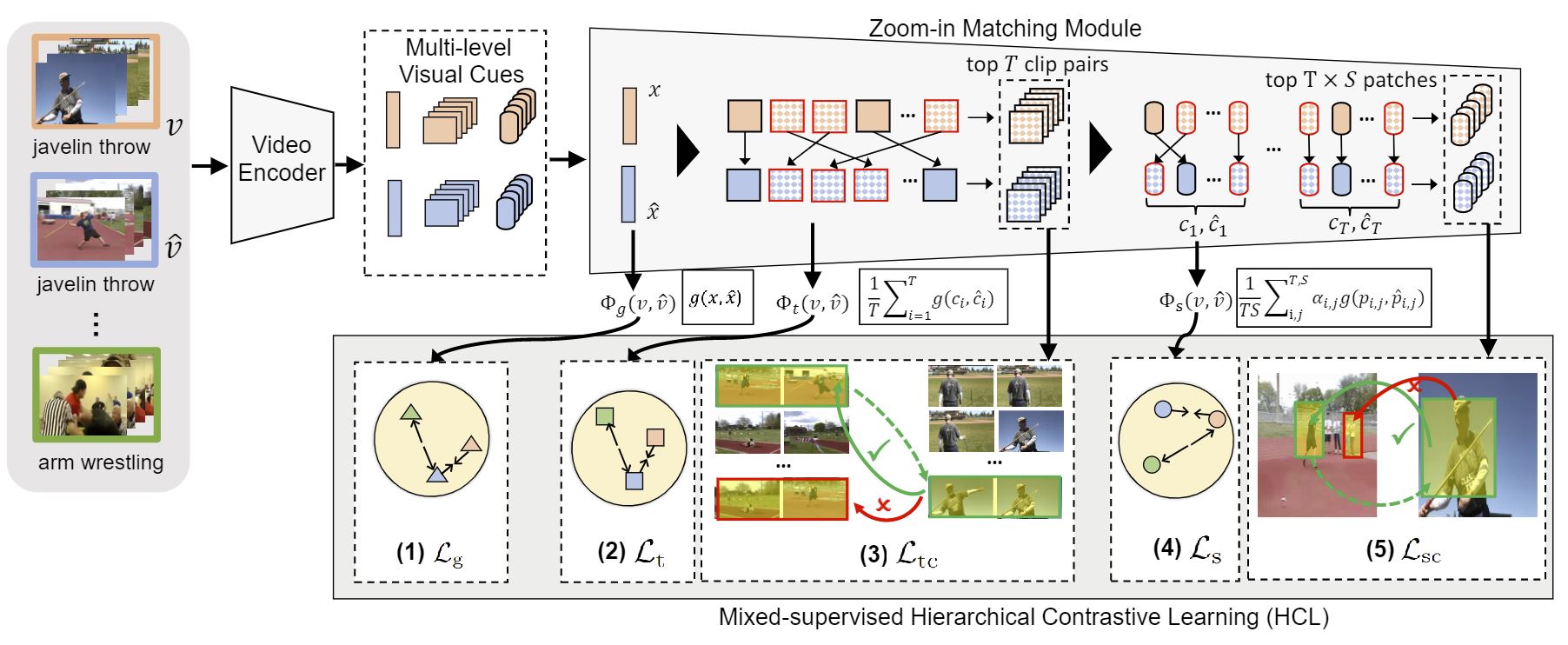
Few-shot Action Recognition with Hierarchical Matching and Contrastive Learning, Sipeng Zheng, Shizhe Chen, Qin Jin
ECCV22
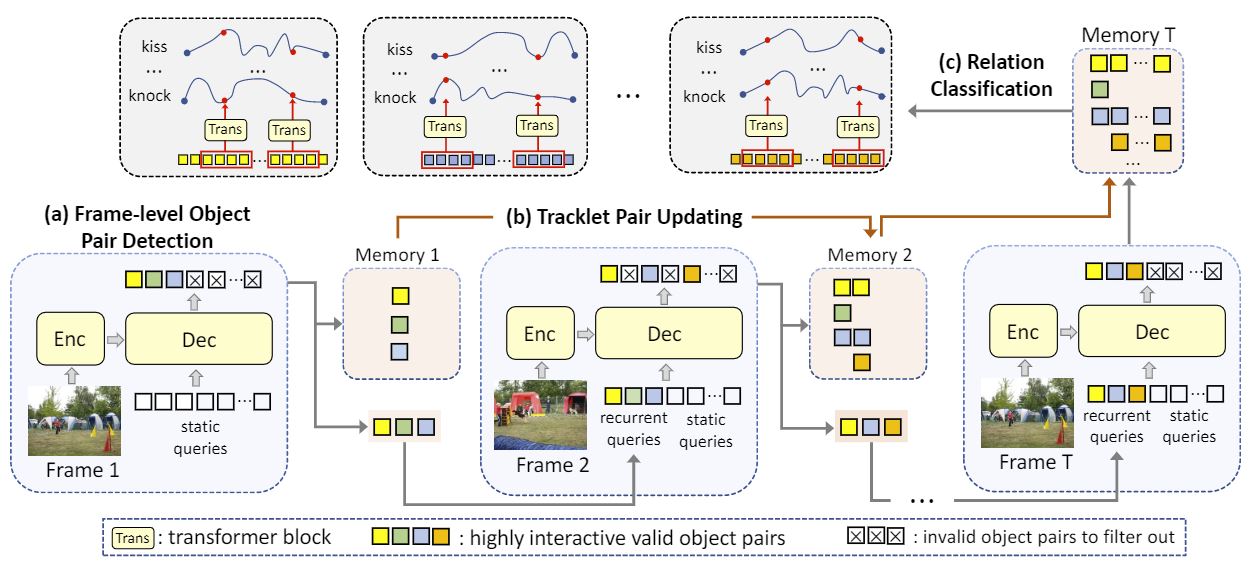
VRDFormer: End-to-end video visual relation detection with transformer, Sipeng Zheng, Shizhe Chen, Qin Jin
CVPR22 (Oral 4.14%)
Paper List
-
Arxiv 2026Human-Centric Transferable Tactile Pre-Training for Dexterous Robotic Manipulation, Chi Zhang, Penglin Cai, Ziheng Xi, Haoqi Yuan, Hao Luo, Wanpeng Zhang, Sipeng Zheng, Chaoyi Xu, Zongqing Lu. -
Arxiv 2026Being-H0.7: A Latent World-Action Model from Egocentric Videos, BeingBeyond Team, Blog | Code (coming soon). -
Arxiv 2026Conservative Offline Robot Policy Learning via Posterior-Transition Reweighting, Wanpeng Zhang, Hao Luo, Sipeng Zheng, Yicheng Feng, Haiweng Xu, Ziheng Xi, Chaoyi Xu, Haoqi Yuan, Zongqing Lu. -
Arxiv 2026Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization, BeingBeyond Team, Blog | Code |Model.
-
ACM-MM 2026Robust Motion Generation using Part-level Reliable Data from Videos, Boyuan Li, Sipeng Zheng, Bin Cao, Ruihua Song, Zongqing Lu. -
ECCV 2026DiG-Flow: Discrepancy-Guided Flow Matching for Robust VLA Models, Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Yicheng Feng, Sipeng Zheng, Qin Jin, Zongqing Lu, Blog | Code. -
ECCV 2026RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control, Junpeng Yue, Zepeng Wang, Yuxuan Wang, Weishuai Zeng, Jiangxing Wang, Xinrun Xu, Yu Zhang, Sipeng Zheng, Ziluo Ding, Zongqing Lu, Page. -
ECCV 2026Unmasking the Illusion of Embodied Reasoning in Vision-Language-Action Models, Haiweng Xu, Sipeng Zheng, Hao Luo, Wanpeng Zhang, Ziheng Xi, Zongqing Lu, Code. -
ICML 2026Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos, BeingBeyond Team, Blog | Code | -
CVPR 2026Predictive Embedding as Latent Action: Towards VLA Pretraining in the Wild, Hao Luo, Ye Wang, Wanpeng Zhang, Haoqi Yuan, Yicheng Feng, Haiweng Xu, Sipeng Zheng, Zongqing Lu, -
CVPR 2026OpenT2M: No-frill Motion Generation with Open-source, Large-scale, High-quality Data, Bin Cao, Sipeng Zheng, Hao Luo, Boyuan Li, Jing Liu, Zongqing Lu. -
CVPR 2026Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos, Yicheng Feng, Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Sipeng Zheng, Zongqing Lu, Page | Project. -
NeurIPS 2025OpenMMEgo: Enhancing Egocentric Understanding for LMMs with Open Weights and Data, Hao Luo, Zihao Yue, Wanpeng Zhang, Yicheng Feng, Sipeng Zheng, Deheng Ye, Zongqing Lu. Boshen Xu, Yuting Mei, Xinbi Liu, Sipeng Zheng, Jin Qin. -
NeurIPS 2025EgoDTM: Towards 3D-Aware Egocentric Video-Language Pretraining, Boshen Xu, Yuting Mei, Xinbi Liu, Sipeng Zheng, Jin Qin, Code. -
EMNLP 2025Taking Notes Brings Focus? Towards Multi-Turn Multimodal Dialogue Learning, Jiazheng Liu, Sipeng Zheng, Börje F Karlsson, Zongqing Lu. -
ICCV 2025Unified Multimodal Understanding via Byte-Pair Visual Encoding, Wanpeng Zhang, Yicheng Feng, Hao Luo, Yijiang Li, Zihao Yue, Sipeng Zheng, Zongqing Lu, Blog | Code | Page. -
ICCV 2025MotionCtrl: A Real-time Controllable Vision-Language-Motion Model, Bin Cao*, Sipeng Zheng*, Ye Wang, Lujie Xia, Qianshan Wei, Qin Jin, Jing Liu, Zongqing Lu. -
ICCV 2025VideoOrion: Tokenizing Object Dynamics in Videos, Yicheng Feng*, Yijiang Li*, Wanpeng Zhang, Sipeng Zheng, Zongqing Lu. -
Arxiv 2025QuadrupedGPT: Towards a Versatile Quadruped Agent in Open-ended Worlds, Yuting Mei*, Ye Wang*, Sipeng Zheng, Qin Jin, Page. -
ICML 2025Scaling Large Motion Models with Million-Level Human Motions, Ye Wang*, Sipeng Zheng*, Bin Cao, Qianshan Wei, Weishuai Zeng, Qin Jin, Zongqing Lu, Page. -
ICLR 2025EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?, Boshen Xu, Ziheng Wang, Yang Du, Zhinan Song, Sipeng Zheng, Qin Jin, Code. -
ICLR 2025From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities, Wanpeng Zhang, Zilong Xie, Yicheng Feng, Yijiang Li, Xingrun Xing, Sipeng Zheng, Zongqing Lu, Page. -
3DV 2025SPAFormer: Sequential 3D Part Assembly with Transformers, Boshen Xu, Sipeng Zheng, Qin Jin, Code. -
ECCV 2024UniCode: Learning a Unified Codebook for Multimodal Large Language Models, Sipeng Zheng, Bohan Zhou, Yicheng Feng, Ye Wang, Zongqing Lu. -
ICLR 2024Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds, Sipeng Zheng, Jiazheng Liu, Yicheng Feng, Zongqing Lu, Page. -
NAACL 2024LLaMA Rider: Spurring Large Language Models to Explore the Open World, Yicheng Feng, Yuxuan Wang, Jiazheng Liu, Sipeng Zheng, Zongqing Lu, Page. -
ACM-MM 2023POV: Prompt-Oriented View-agnostic Learning for Egocentric Hand-Object Interaction in the Multi-view World, Boshen Xu, Sipeng Zheng, Qin Jin, Page | Code. -
AAAI 2023No-frills Temporal Video Grounding: Multi-Scale Neighboring Attention and Zoom-in Boundary Detection, Qi Zhang, Sipeng Zheng, Qin Jin, Code. -
CVPR 2023Open-Category Human-Object Interaction Pre-Training via Language Modeling Framework, Sipeng Zheng, Boshen Xu, Qin Jin. -
AAAI 2023Accommodating audio modality in CLIP for multimodal processing, Ludan Ruan, Anwen Hu, Yuqing Song, Lliang Zhang, Sipeng Zheng, Qin Jin. -
IEEC 2023Anchor-Based Detection for Natural Language Localization in Ego-Centric Videos, Sipeng Zheng, Bei Liu, Jianlong Fu, Wen-Huang Cheng, Code. -
ECCV 2022Few-shot Action Recognition with Hierarchical Matching and Contrastive Learning, Sipeng Zheng, Shizhen Chen, Qin Jin, Code. -
CVPR 2022VRDFormer: End-to-end video visual relation detection with transformer, Sipeng Zheng, Shizhe Chen, Qin Jin, Code. -
CVPR 2022 workshopExploring anchor-based detection for ego4d natural language query, Sipeng Zheng, Qi Zhang, Bei Liu, Qin Jin, Jianlong Fu, , Code. -
ICME 2020Skeleton-based interactive graph network for human object interaction detection, Sipeng Zheng, Shizhe Chen, Qin Jin, , Code. -
ACM-MM 2019Visual relation detection with multi-level attention, Sipeng Zheng, Shizhe Chen, Qin Jin. -
ACM-MM 2019Relation understanding in videos, Sipeng Zheng, Xiangyu Chen, Shizhe Chen, Qin Jin.
Honors and Awards
- 2025 Ranked 1st in GemBench Challenge at CVPR 2025 Workshop GRAIL.
- 2022 Ranked 3rd in CVPR 2022 Ego4D Natural Language Query Challenge.
- 2021 Ranked 3rd in NIST TRECVID 2021 Ad-hoc Video Search (AVS) Challenge.
- 2021 Ranked 2nd in CVPR 2021 HOMAGE Scene-graph Generation Challenge.
- 2020 Ranked 2nd in ACM MM 2020 Video Relationship Understanding Grand Challenge.
- 2019 Ranked 2nd in ACM MM 2019 Video Relationship Understanding Grand Challenge.
- 2022 National Scholarship for Ph.D. Students.
- 2019 Best Method Prize in ACM MM 2019 Grand Challenge.
- 2019 First Class Scholarship for Ph.D. Students from 2018 to 2021.
- 2015 First Prize in National University Mathematical Modeling Competition of Beijing Area.
Education
- 2018.09 - 2023.06, PhD, Computer Science and Engineering, Renmin University of China, China.
- 2014.09 - 2018.06, Undergraduate, Computer Science and Engineering, Renmin University of China, China.
Work Experience
- 2025.05 - now, Research Scientist, BeingBeyond, Beijing, China.
- 2023.07 - 2025.05, Researcher, Beijing Academy of Artificial Intelligence, Beijing, China.
- 2022.04 - 2022.10, Research Intern, Microsoft Research Asia, Beijing, China.
- 2021.11 - 2022.04, Research Intern, Beijing Academy of Artificial Intelligence, Beijing, China.
Services
- Conference Reviewer for CVPR, ICCV, ECCV, ACCV, NeurIPS, AAAI, ACM MM.
- Journal Reviewer for IJCV, TCSVT, TMM, JATS.