Open-Category Human-Object Interaction Pre-Training via Language Modeling Framework
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
Recommended citation: S Zheng, B Xu, Q Jin. "Open-Category Human-Object Interaction Pre-Training via Language Modeling Framework." 2023 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19392-19402. https://openaccess.thecvf.com/content/CVPR2023/papers/Zheng_Open-Category_Human-Object_Interaction_Pre-Training_via_Language_Modeling_Framework_CVPR_2023_paper.pdf
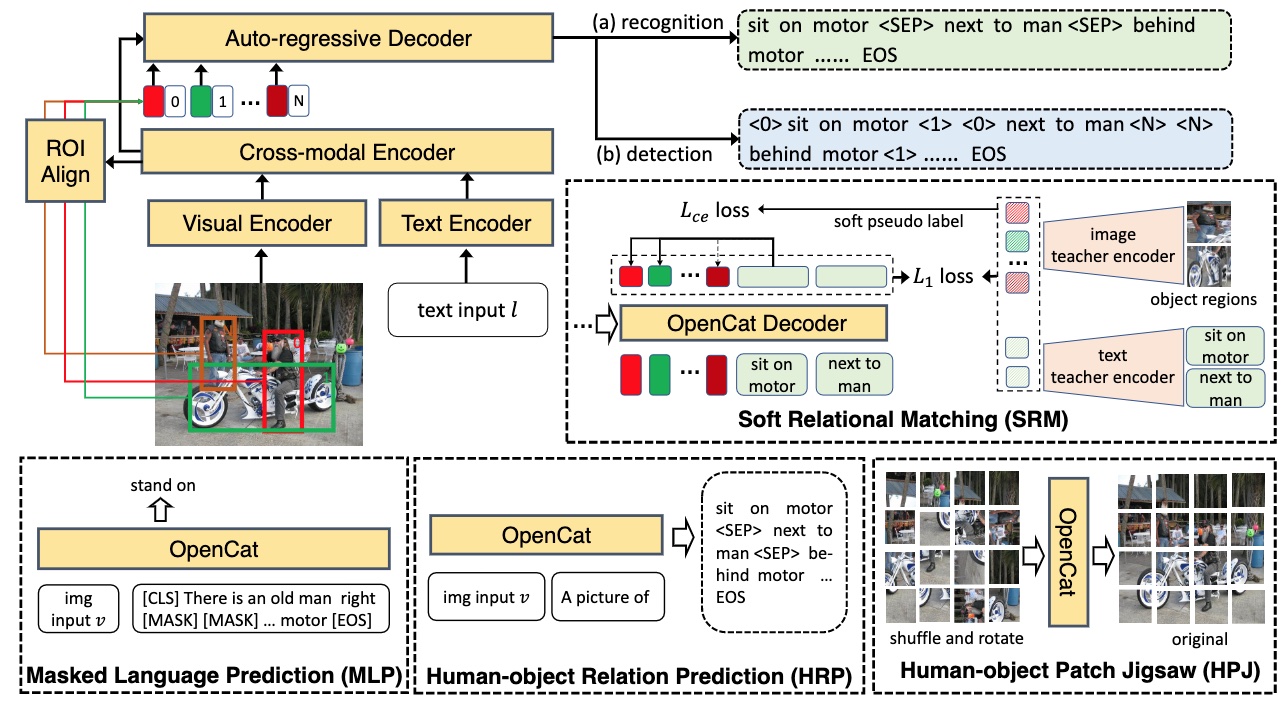
Human-object interaction (HOI) has long been plagued by the conflict between limited supervised data and a vast number of possible interaction combinations in real life. Current methods trained from closed-set data predict HOIs as fixed-dimension logits, which restricts their scalability to open-set categories. To address this issue, we introduce OpenCat, a language modeling framework that reformulates HOI prediction as sequence generation. By converting HOI triplets into a token sequence through a serialization scheme, our model is able to exploit the open-set vocabulary of the language modeling framework to predict novel interaction classes with a high degree of freedom. In addition, inspired by the great success of vision-language pre-training, we collect a large amount of weakly-supervised data related to HOI from image-caption pairs, and devise several auxiliary proxy tasks, including soft relational matching and human-object relation prediction, to pre-train our model. Extensive experiments show that our OpenCat significantly boosts HOI performance, particularly on a broad range of rare and unseen categories.