POV: Prompt-Oriented View-agnostic Learning for Egocentric Hand-Object Interaction in the Multi-view World
Published in Proceedings of the 31st ACM International Conference on Multimedia, 2023
Recommended citation: B Xu, S Zheng, Q Jin. "POV: Prompt-Oriented View-agnostic Learning for Egocentric Hand-Object Interaction in the Multi-view World." 2023 Proceedings of the 31st ACM International Conference on Multimedia. 2807-2816. https://doi.org/10.1007/s00704-018-2617-z
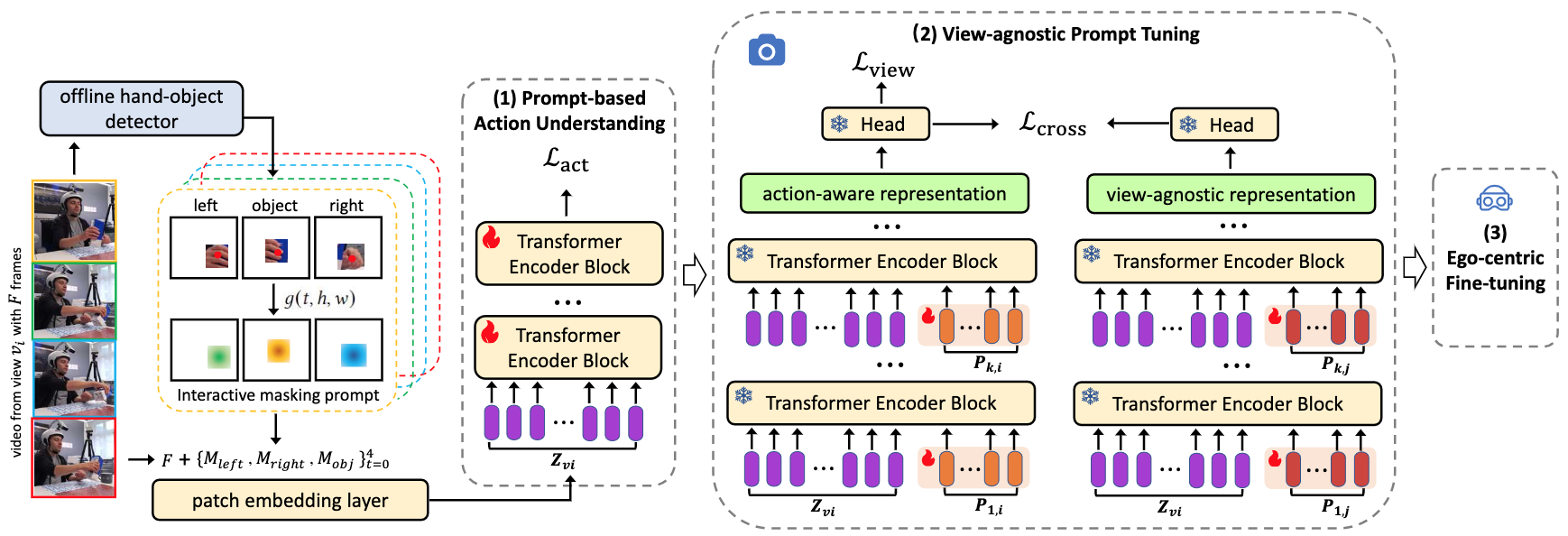
We humans are good at translating third-person observations of hand-object interactions (HOI) into an egocentric view. However, current methods struggle to replicate this ability of view adaptation from third-person to first-person. Although some approaches attempt to learn view-agnostic representation from large-scale video datasets, they ignore the relationships among multiple third-person views. To this end, we propose a Prompt-Oriented View-agnostic learning (POV) framework in this paper, which enables this view adaptation with few egocentric videos. Specifically, We introduce interactive masking prompts at the frame level to capture fine-grained action information, and view-aware prompts at the token level to learn view-agnostic representation. To verify our method, we establish two benchmarks for transferring from multiple third-person views to the egocentric view. Our extensive experiments on these benchmarks demonstrate the efficiency and effectiveness of our POV framework and prompt tuning techniques in terms of view adaptation and view generalization.