Few-shot Action Recognition with Hierarchical Matching and Contrastive Learning
Published in European Conference on Computer Vision, 2022
Recommended citation: S Zheng, S Chen, Q Jin. "Few-shot Action Recognition with Hierarchical Matching and Contrastive Learning." 2022 European Conference on Computer Vision. 297-313. https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136640293.pdf
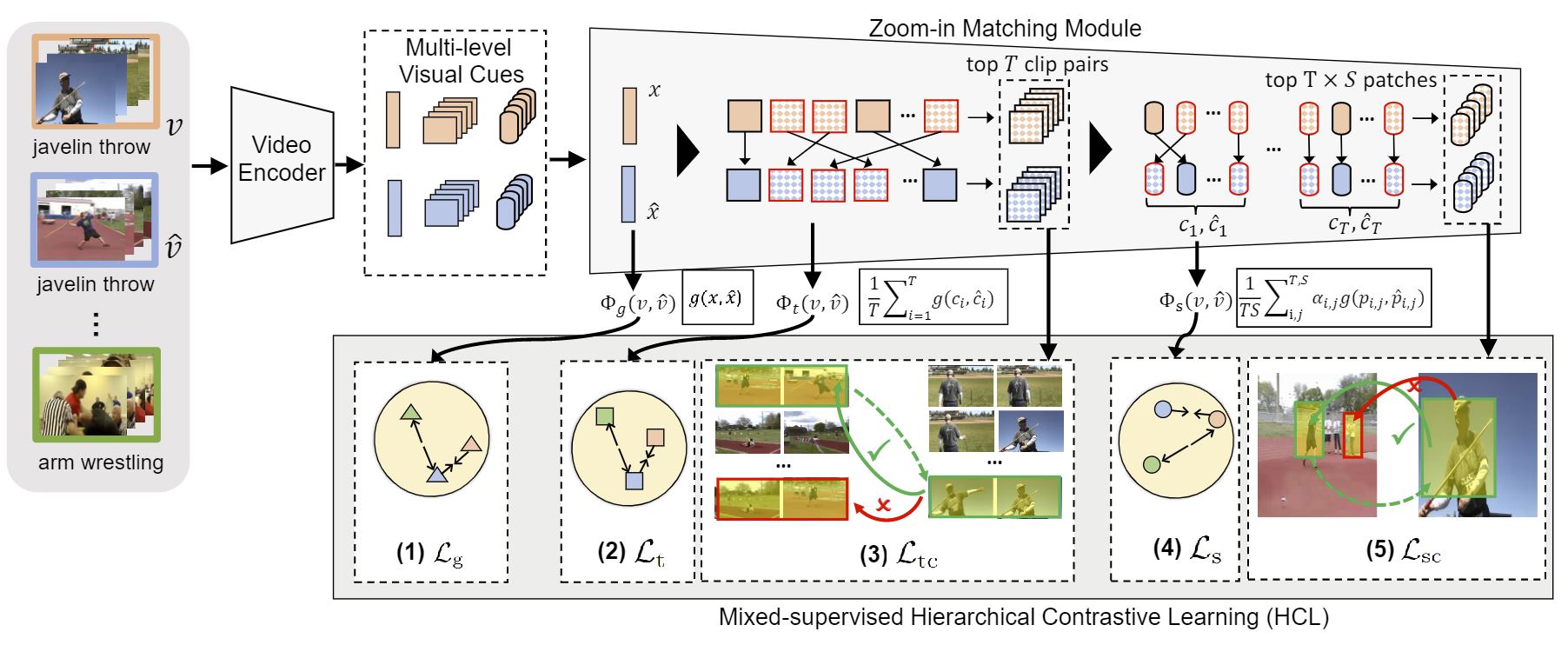
Few-shot action recognition aims to recognize actions in test videos based on limited annotated data of target action classes. The dominant approaches project videos into a metric space and classify videos via nearest neighboring. They mainly measure video similarities using global or temporal alignment alone, while an optimum matching should be multi-level. However, the complexity of learning coarse-to-fine matching quickly rises as we focus on finer-grained visual cues, and the lack of detailed local supervision is another challenge. In this work, we propose a hierarchical matching model to support comprehensive similarity measure at global, temporal and spatial levels via a zoom-in matching module. We further propose a mixed-supervised hierarchical contrastive learning (HCL), which not only employs supervised contrastive learning to differentiate videos at different levels, but also utilizes cycle consistency as weak supervision to align discriminative temporal clips or spatial patches. Our model achieves state-of-the-art performance on four benchmarks especially under the most challenging 1-shot recognition setting.