VRDFormer: End-to-end video visual relation detection with transformer
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
Recommended citation: S Zheng, S Chen, Q Jin. "VRDFormer: End-to-end video visual relation detection with transformer." 2022 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18836-18846. https://openaccess.thecvf.com/content/CVPR2022/papers/Zheng_VRDFormer_End-to-End_Video_Visual_Relation_Detection_With_Transformers_CVPR_2022_paper.pdf
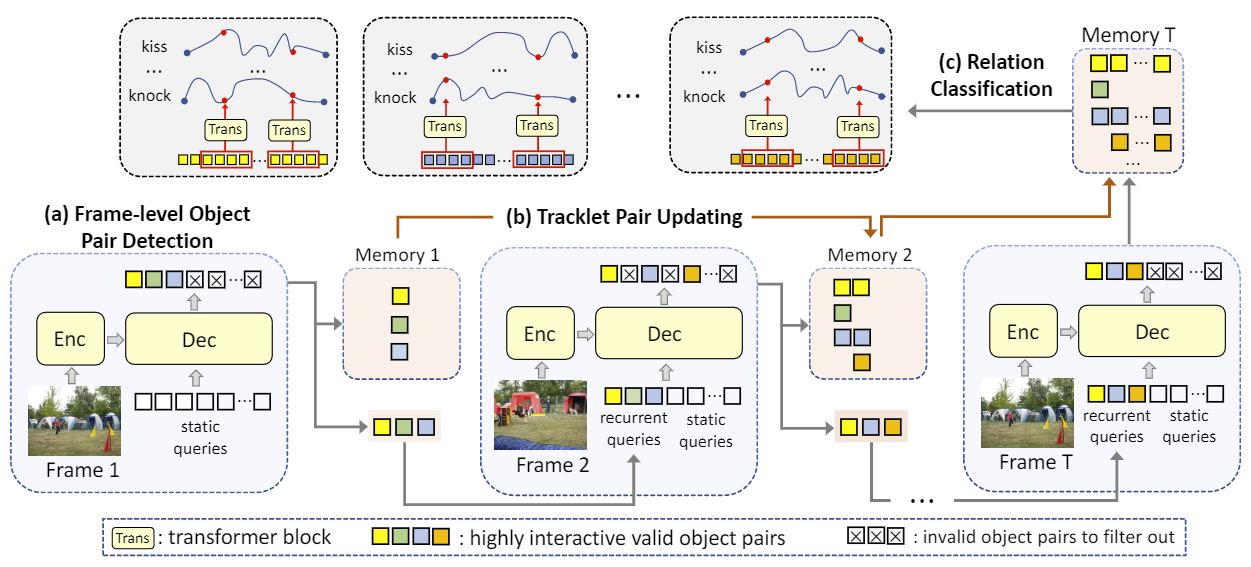
Visual relation understanding plays an essential role for holistic video understanding. Most previous works adopt a multi-stage framework for video visual relation detection (VidVRD), which cannot capture long-term spatiotemporal contexts in different stages and also suffers from inefficiency. In this paper, we propose a transformerbased framework called VRDFormer to unify these decoupling stages. Our model exploits a query-based approach to autoregressively generate relation instances. We specifically design static queries and recurrent queries to enable efficient object pair tracking with spatio-temporal contexts. The model is jointly trained with object pair detection and relation classification. Extensive experiments on two benchmark datasets, ImageNet-VidVRD and VidOR, demonstrate the effectiveness of the proposed VRDFormer, which achieves the state-of-the-art performance on both relation detection and relation tagging tasks.